| CPC G06F 16/2365 (2019.01) [G06N 20/00 (2019.01)] | 14 Claims |
|
1. A system comprising:
a memory having instructions stored thereon, and a processor configured to read the instructions to:
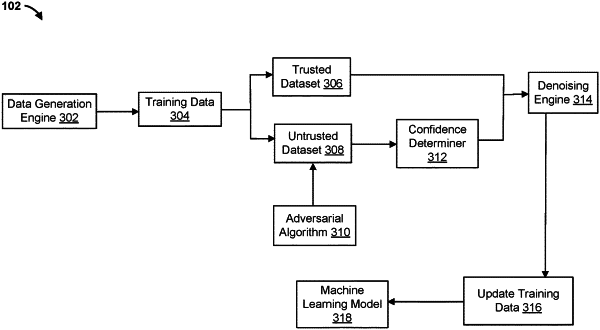
obtain a dataset from a database;
select a first portion of the dataset including trusted data of the dataset such that a remaining dataset exists, wherein the first portion of the dataset is selected using stratified sampling of the dataset;
generate a first classification model based on the remaining dataset;
generate an updated untrusted dataset by simulating exposure of the remaining dataset to an adversarial process;
generate a second classification model based on the updated untrusted dataset;
for each data sample of the remaining dataset, determine whether a corresponding observed label is a true label for the data sample based at least in part on the first portion of the dataset, wherein the determination is based on an estimated reverse transformation function for the first classification model and the second classification model;
generate an updated remaining dataset based on the determination, for each data sample of the remaining dataset, whether the observed label is a true label for the data sample; and
train a machine learning model based on the updated remaining dataset and the first portion of the dataset by:
for each data sample of the remaining dataset, determining a probability of the corresponding observed label being a true label; and
determining, for each data sample of the remaining dataset, whether the corresponding observed label is a true label based on the probability, wherein determining whether the corresponding observed label is the true label is based on a confidence of the processor to have correctly determined the probability.
|