| CPC G16H 50/20 (2018.01) [G06F 18/2411 (2023.01); G06N 3/04 (2013.01); G16H 10/60 (2018.01); G16H 50/70 (2018.01)] | 16 Claims |
|
1. A computer-implemented method, comprising:
continually obtaining, by one or more processors in a distributed computing environment, electronic medical records comprising a plurality of machine-readable data sets related to a patient population diagnosed with a medical condition from one or more databases, wherein machine-readable data comprising the plurality of machine-readable data sets are obtained from different computing nodes in the distributed computing environment, wherein the medical condition is an orphan disease;
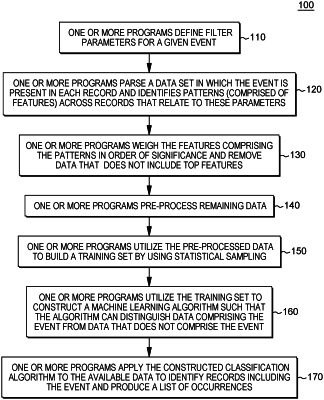
continually applying, by the one or more processors, a neural network to the plurality of machine-readable data sets to machine learn an optimal set of features for classifying patients into a plurality of categories related to presence or progression of the medical condition, wherein the machine learned optimal set of features comprise features identified by the neural network as occurring over the plurality of machine-readable data sets and weighted by the neural network;
continually generating, by the one or more processors, based on the machine learned optimal set of features, intermediate features, based on the weightings of a portion of the machine learned optimal set of features, wherein the intermediate features comprise a model of the medical condition;
obtaining, by the one or more processors, at a given time, a first one or more data sets related to a patient population not diagnosed with the medical condition;
evaluating, by the one or more processors, a portion of records comprising the first one or more data sets related to the patient population not diagnosed with the medical condition and classifying the portion of the records, based on the evaluating, into the plurality of categories related to the medical condition, wherein each category related to the medical condition represents a likelihood of having or developing the medical condition during a defined timeline, based on a current model, wherein based on the continually obtaining the plurality of machine-readable data sets, the continually applying the neural network to the plurality of machine-readable data sets, and the continually generating the intermediate features, the current model is a version of the model generated in real-time based on the given time;
obtaining, by the one or more processors, at a second given time a second one or more data sets related to the patient population not diagnosed with the medical condition;
classifying, by the one or more processors, a portion of records comprising the second one or more data sets into a plurality of categories related to the medical condition, based on a new current model, wherein based on the continually obtaining, continually applying, and continually generating, the new current model is a version of the model generated in real-time at the second given time, wherein the new current model is different from the current model based on changes in machine-readable data comprising the plurality of the machine-readable data sets between the given time and the second given time, wherein the intermediate features automatically change temporally, based on the changes in the machine-readable data comprising the plurality of machine-readable data sets over time, and wherein data comprising the first one or more data sets and the second one or more data sets are related to patients not diagnosed with the medical condition;
based on a frequency of features in the plurality of data sets, identifying, by the one or more processors, additional common features in the plurality of machine-readable data sets and weighting the additional common features based on frequency of occurrence in the plurality of machine-readable data sets, wherein the additional common features comprise mutual information, wherein the additional common features comprise one or more features of the common features with mutual information values above a predefined threshold;
selecting, by the one or more processors, a portion of the additional common features, wherein the portion of the additional common features comprises a smallest subset of features from the one or more features that collectively contain a majority of the mutual information;
generating, by the one or more processors, one or more patterns comprising the portion of the additional common features;
generating, by the one or more processors, utilizing one or more support vector machines, one or more classifier algorithms based on the one or more patterns comprising the portion of the additional common features, the one or more classifier algorithms to identify presence or absence of the medical condition in an undiagnosed patient based on absence or presence of features comprising the one or more patterns comprising the portion of the additional common features in data related to the undiagnosed patient;
tuning, by the one or more processors, based on the current model, the one or more classifier algorithms;
obtaining, by the one or more processors, a third one or more data sets related to the patient population not diagnosed with the medical condition; and
classifying, by the one or more processors, based on the one or more tuned classifier algorithms, a third portion of records comprising the third one or more data sets into the plurality of categories related to the medical condition.
|