| CPC G10L 25/66 (2013.01) [A61B 5/0823 (2013.01); A61B 5/4803 (2013.01); A61B 5/7267 (2013.01); A61B 5/7282 (2013.01); G10L 15/02 (2013.01); G10L 15/04 (2013.01); G10L 15/063 (2013.01); G10L 25/30 (2013.01); G10L 25/51 (2013.01); G10L 25/78 (2013.01); G16H 40/67 (2018.01)] | 20 Claims |
|
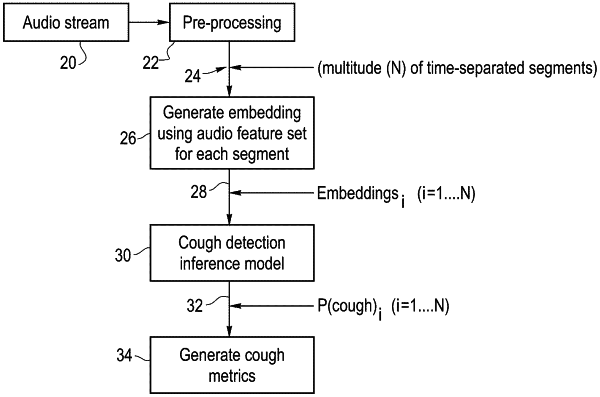
1. A computer-implemented method for detecting a cough in an audio stream, comprising:
performing one or more pre-processing steps on the audio stream to generate an input audio sequence comprising a plurality of time-separated audio segments;
generating an embedding for each of the segments of the input audio sequence using an audio feature set generated by a self-supervised triplet loss embedding model, the embedding model having been trained to learn the audio feature set in a self-supervised triplet loss manner from a plurality of speech audio clips from a speech dataset;
providing the embedding for each of the segments to a model performing cough detection inference, the model generating a probability that each of the segments of the input audio sequence includes a cough episode; and
generating cough metrics for each of the cough episodes detected in the input audio sequence.
|