| CPC G10L 15/26 (2013.01) [G10L 15/02 (2013.01); G10L 15/04 (2013.01); G10L 25/30 (2013.01); G10L 25/78 (2013.01); G10L 2025/783 (2013.01)] | 30 Claims |
|
1. An apparatus comprising at least one processor and a storage to store instructions that, when executed by the at least one processor, cause the at least one processor to perform operations comprising:
receive, from a requesting device via a network, a request to perform speech-to-text conversion of a specified speech data set representing speech audio;
in response to the request, the at least one processor is caused to perform preprocessing operations comprising:
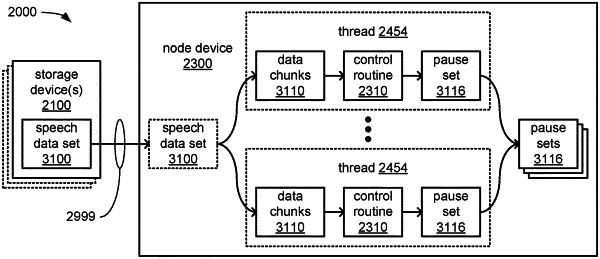
within a first thread of a thread pool that comprises multiple threads of execution supported by the at least one processor, perform a first pause detection technique to identify a first set of likely sentence pauses in the speech audio;
within a second thread of the thread pool, perform a second pause detection technique to identify a second set of likely sentence pauses in the speech audio; and
perform a speaker diarization technique to identify a set of likely speaker changes in the speech audio; and
in response to the request, the at least one processor is caused to perform speech-to-text processing operations comprising:
divide the speech data set into multiple data segments that each represent a speech segment of multiple speech segments of the speech audio based on a combination of at least the first set of likely sentence pauses, the second set of likely sentence pauses, and the set of likely speaker changes;
use at least an acoustic model with each data segment of the multiple data segments to identify likely speech sounds in the speech audio; and
generate a transcript of the speech data set based, at least in part, on the identified likely speech sounds, or transmit an indication of the generation of the transcript to the requesting device.
|