| CPC G10L 15/1815 (2013.01) [G06F 16/61 (2019.01); G06N 5/04 (2013.01); G06Q 10/107 (2013.01); G06Q 30/016 (2013.01); G10L 15/22 (2013.01); G10L 15/30 (2013.01); G10L 15/32 (2013.01); H04L 9/0643 (2013.01); H04L 9/3242 (2013.01)] | 21 Claims |
|
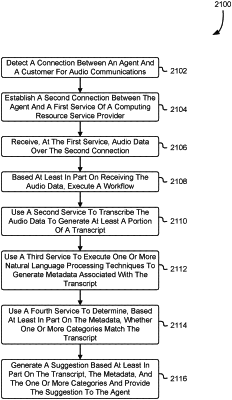
1. A computer-implemented method, comprising:
receiving, at a frontend service, a request to process a set of data for a client;
creating a job based at least in part on the request; and
as a result of the job being created, executing a step functions workflow comprising a plurality of steps to collectively:
obtain a copy of the set of data, the copy including a subset of audio data;
utilize an artificial intelligence speech-to-text service to generate transcripts for the subset of audio data, wherein a portion of the transcript is reconstructed based at least in part on fragments of the transcript that correspond to separate portions of the audio data obtained at different times;
as a result of reconstructing the portion of the transcript, use a natural language processing (NLP) service to perform a set of NLP techniques on the transcripts to generate metadata encoding one or more characteristics of the transcripts;
use a categorization service to identify one or more categories that match the subset of audio data, wherein the one or more categories are defined based at least in part on rules that evaluate content and audio characteristics of audio data;
generate an output that encodes at least the transcripts, the metadata, and the one or more categories; and
provide the output to the client.
|