| CPC G06Q 30/0211 (2013.01) [G06N 3/08 (2013.01); G06Q 30/0208 (2013.01); G06Q 50/30 (2013.01); G06Q 30/0219 (2013.01)] | 20 Claims |
|
1. A transportation hailing system, comprising:
a plurality of client devices, each of the client devices in communication with a network and executing an application to engage a transportation service;
a plurality of transportation devices, each of the transportation devices being associated with one of a plurality of drivers and executing an application to offer the transportation service;
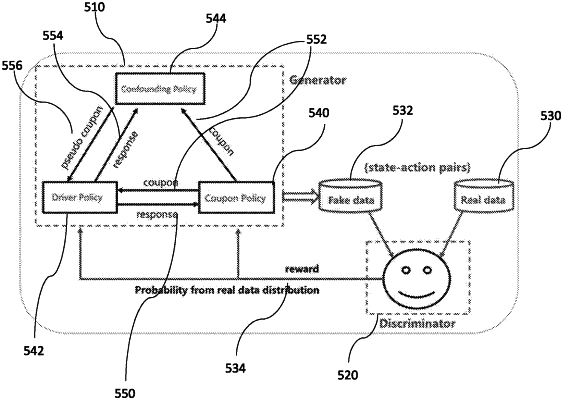
a database storing state and action data for each driver, the state data being associated with the transportation service provided by the driver and the action data being associated with the driver receiving an incentive;
an incentive system coupled to the plurality of transportation devices, the database, and client devices via the network, the incentive system including:
a joint policy simulator, configure to generate, based on the state and action data for each driver, a simulated action of the each driver using a joint policy model, wherein the joint policy model includes an incentive policy, a confounding incentive policy, and an incentive object policy;
a discriminator, configure to generate rewards corresponding to the simulated action;
a reinforcement learning system, configure to provide an optimized incentive policy from the simulated action based on the rewards; and
an incentive server, configure to communicate a selected incentive to at least some of the transportation devices according to the optimized incentive policy, wherein the joint policy model is generated according to a training process including:
obtaining sample state and action data of a plurality of sample drivers;
for each of the plurality of sample drivers,
generating a sample incentive for the sample driver by inputting the sample state and action data of the sample driver into the incentive policy;
generating another sample incentive for the sample driver by inputting the sample state and action data of the sample driver and the sample incentive into the confounding incentive policy;
generating a simulated action of the sample driver by inputting the sample state and action data of the sample driver, the sample incentive, and the another sample incentive into the incentive object policy;
determining a reward based on an output of the discriminator, the output of the discriminator being obtained by inputting the simulated action and the sample state and action data into the discriminator; and
generating the joint policy model based on the reward of each of the plurality of sample drivers.
|