| CPC G06N 20/00 (2019.01) [G06F 18/2113 (2023.01); G06F 30/20 (2020.01); G06N 7/01 (2023.01)] | 17 Claims |
|
1. A method for multivariate machine-learning simulations, the method comprising:
receiving, with a processing device, an input dataset comprising marketing data for a marketing simulation performed by a trained machine-learning model, wherein the input dataset includes input features describing aspects of a marketing scenario to be simulated using the marketing simulation;
modifying, with the processing device, the input dataset for use by the trained machine-learning model, wherein modifying the input dataset comprises:
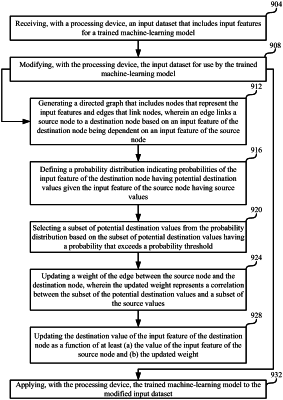
initiating a directed acyclic graph that includes nodes representing the input features and initially omits edges;
iteratively modifying the directed acyclic graph while determining a correlation coefficient for two or more of the input features in the directed acyclic graph subject to modification, wherein the correlation coefficient defines a relationship between the two or more of the input features;
maintaining edges between pairs of input features in response to an increase in a score determined by the correlation coefficient to generate the directed acyclic graph including nodes and the edges that link the nodes, wherein an edge links a source node to a destination node based on an input feature of the destination node being dependent on an input feature of the source node as indicated by the increase in the score,
defining a probability distribution indicating probabilities of the input feature of the destination node having potential destination values given the input feature of the source node having source values,
selecting a subset of potential destination values from the probability distribution based on the subset of potential destination values having a probability that exceeds a probability threshold, wherein the probability threshold is configured to determine potential destination values of the input features corresponding to a user action being more likely than not to occur,
updating a weight of the edge between the source node and the destination node, wherein the updated weight represents a correlation between destination marketing inputs represented by the subset of the potential destination values and source marketing inputs represented by a subset of the source values, and
updating a destination value of the input feature of the destination node as a function of at least (a) a value of the input feature of the source node and (b) the updated weight; and
applying, with the processing device, the trained machine-learning model to the modified input dataset to produce a predictive output based on the marketing data.
|