| CPC G06F 40/30 (2020.01) [G06F 1/3206 (2013.01); G06F 3/011 (2013.01); G06F 3/04815 (2013.01); G06N 5/02 (2013.01); G06N 5/046 (2013.01); G06T 19/006 (2013.01); G06T 19/20 (2013.01); G06T 2219/2004 (2013.01)] | 19 Claims |
|
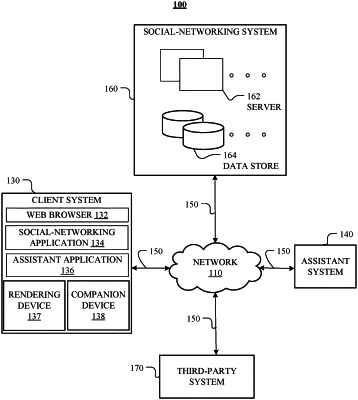
1. A method comprising, by one or more computing systems:
receiving a user request to automatically debug a natural-language understanding (NLU) model;
accessing a plurality of predicted semantic representations generated by the NLU model, wherein the plurality of predicted semantic representations are associated with a plurality of dialog sessions, respectively, wherein each dialog session is between a user from a plurality of users and an assistant xbot associated with the NLU model;
generating, based on an auto-correction model, a plurality of expected semantic representations associated with the plurality of dialog sessions, wherein the auto-correction model is learned from a plurality of dialog training samples generated based on active learning;
identifying, based on a comparison between the predicted semantic representations and the expected semantic representations, one or more incorrect semantic representations of the predicted semantic representations; and
automatically correcting the one or more incorrect semantic representations by replacing them with one or more respective expected semantic representations generated by the auto-correction model.
|