| CPC G06F 16/24532 (2019.01) [G06F 16/211 (2019.01)] | 20 Claims |
|
1. A system comprising:
one or more processors; and
one or more non-transitory computer-readable media storing computing instructions configured to run on the one or more processors and perform:
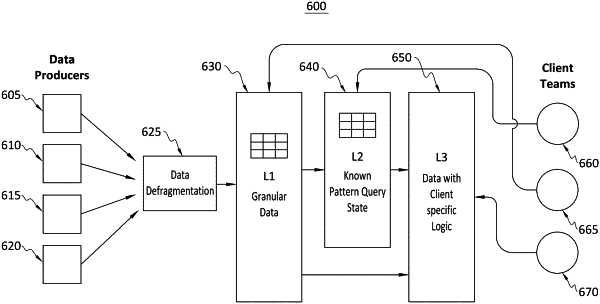
translating event records into a non-relational (NoSQL) schema, wherein translating the event records into the NoSQL schema comprises:
determining access patterns of data clients, wherein dataset layers are based on the access patterns of the data clients;
generating, based on the access patterns, a second layer of the dataset layers, wherein the second layer comprises intermediate states for a subset of queries of the access patterns that exceed a predetermined threshold, wherein the NoSQL schema comprises the dataset layers, wherein the dataset layers comprises a first layer and the second layer, and wherein the first layer comprises user profiles of users; and
periodically updating the second layer in the NoSQL schema as additional queries of the access patterns exceed the predetermined threshold;
defragmenting the event records by assigning user identifiers of the users to the event records received in the event streams from the one or more producers in a user domain object model;
bundling multiple registered queries of a dataset using a scheduling technique, wherein the dataset is homogenous in schema;
running a single table scan of the dataset to process the multiple registered queries of the dataset in parallel; and
generating a respective output responsive to each of the multiple registered queries.
|