|
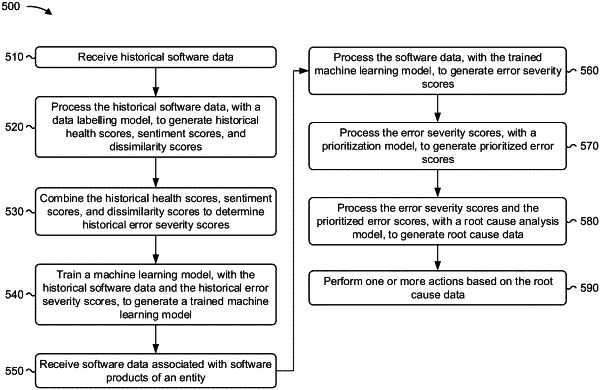
1. A method, comprising: receiving, by a device, historical software data identifying events and logs associated with software products utilized by an entity; processing, by the device, the historical software data, with a data labelling model, to generate historical health scores, historical sentiment scores, and historical dissimilarity scores for the software products; combining, by the device, the historical health scores, the historical sentiment scores, and the historical dissimilarity scores to determine historical error severity scores for the software products; automatically training, by the device, a machine learning model, with the historical software data and the historical error severity scores, to generate a trained machine learning model, wherein the training comprises: determining, based on supervised learning of the machine learning model and based on new input, a prediction; implementing a feedback loop to train the machine learning model; and determining whether the prediction satisfies a threshold level of accuracy, and wherein new historical software data is processed with the trained machine learning model instead of the data labeling model when the prediction satisfies the threshold level of accuracy; receiving, by the device, software data identifying current logs and events associated with software products utilized by the entity; processing, by the device, the software data, with the trained machine learning model, to generate error severity scores for the software products; processing, by the device, the error severity scores, with a prioritization model, to generate prioritized error scores; processing, by the device, the error severity scores and the prioritized error scores, with a root cause analysis model, to generate root cause data identifying root causes associated with the error severity scores; performing, by the device, one or more actions based on the root cause data; receiving, by the device, feedback via the feedback loop; and retraining, by the device and based on the feedback, the trained machine learning model.
|